

General Ideas
When writing your paper, always remember your audience. In particular,
- Your audience is already well-versed in deep learning. Hence, there is no need to describe in detail common deep learning techniques. For example, you can refer to methods such as convolutions, pooling, dropout, batch normalization, recurrent neural networks or L2 regularization without explaining their meaning. If you are using well-known data augmentation methods such as image rotation and translation, you can mention it without showing the augmented images.
- Your audience is busy. Hence, be as short and concise as possible and focus on the key insights of your paper. If the key insight of your paper is the loss function, write out the loss function and elaborate on it. If the key insight of your paper is the model architecture, draw it out and explain the key differences with prior work. For all other details that are common in deep learning, it’s best to state it concisely.
- Your audience may want to reimplement your paper. Hence, it’s important to give details which will help them to reimplement it. Once again, there’s no need to go overboard with details. Think about what will help you re-implement your own paper, and what were the main difficulties you faced when implementing your project were: elaborate more on those points.
The abstract, introduction and conclusion are essential parts of a paper. When writing these parts, it’s important to describe the context of your paper, the motivation behind your work and the key insights drawn from your work. It is also good to mention some results to entice your audience to read more. Refer to the section below on how to write an abstract for more details.
It is also important to provide explanations behind your decisions. Instead of stating that you tuned the number of frozen layers in your network, go beyond that and explain why you believe that a certain hyperparameter is the most important to tune in your network. Doing so also helps your audience fine-tune your network for their own dataset.
How to write an abstract?
 |
In general, the abstract (and the introduction) should address the following questions (from Professor Emma Brunskill):
- What is the problem to be addressed?
- Why is the problem important and why is it hard?
- What are the key limitations of prior work (with associated references)?
- What are the key insights of this paper?
- What are the key results in this paper?
Why is this good?
- Concise and clear
- Addresses most of the above questions
How to describe prior work?
 |
Why is this good?
- Classifies relevant prior work in broad categories. For each category, papers are grouped by their more specific topics.
- Related work is not just mentioned: its relation to this work is explicitly shown.
- The writing is clear and succinct. As a rule of thumb, when writing a paper, remove any words that aren’t bringing meaningful information. For instance, “our convolutional neural network performs object detection by outputting all-sized bounding boxes” could be written as “our object detector outputs bounding boxes” if there’s no need for the reader to know that the object detector is a CNN and outputs bounding boxes of all-size.
- References are mentioned throughout the paragraph to help a curious reader delve deeper into each discussed topic.
How can this be improved?
- Elaborate more on limitations/benefits of prior work. For instance, briefly mention what previous optical flow networks tend to succeed or fail on.
- Elaborate more on which prior work inspired your work, if any.
How to describe or visualize your dataset?
 |
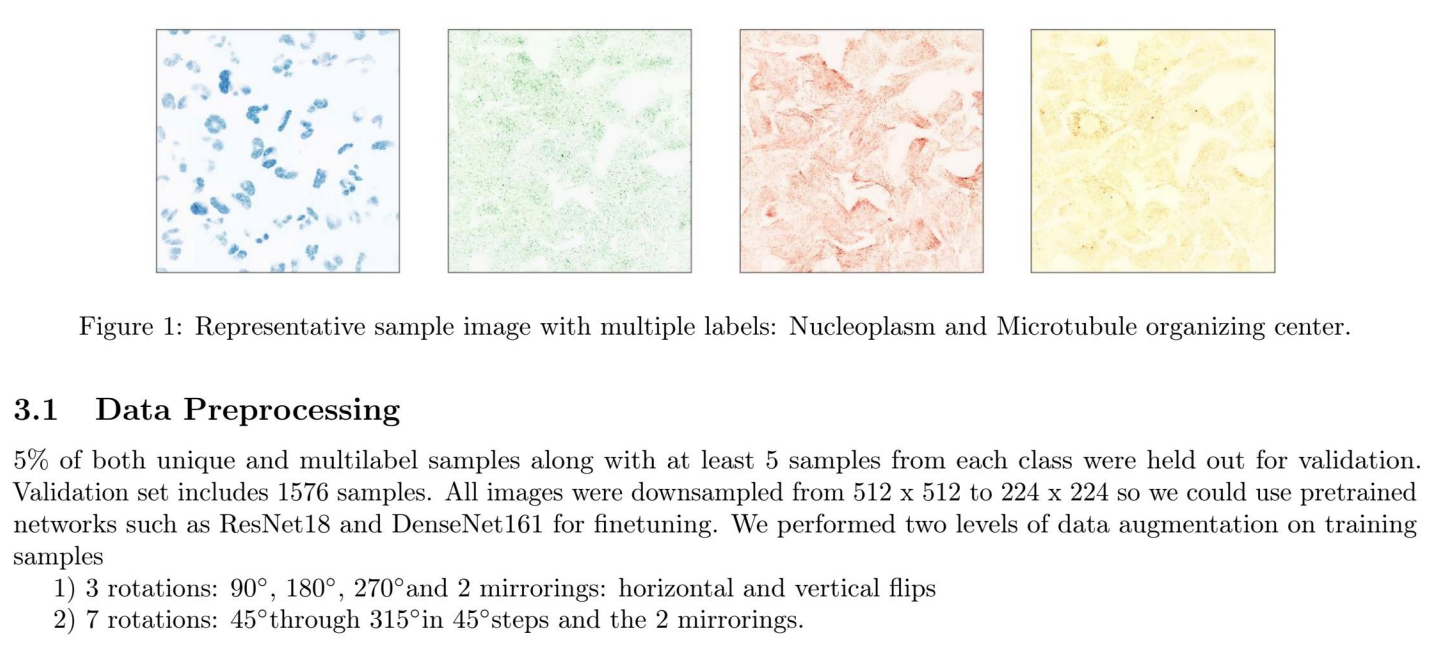 |
Why is this good?
- The authors analyzed their dataset and reported key figures such as dataset size and format. They also displayed sample images from the dataset to help the reader grasp the problem they are solving.
- They also discussed key challenges related to their dataset such as the class imbalance and low-data regime.
- They mentioned using data augmentation and preprocessing to alleviate the data-related challenges.
- You may also include dataset collection/scraping if you’ve done so.
- Other ways to visualize data: word cloud, histograms, etc.
What should be improved?
- The authors haven’t explicitly formulated the split between training, validation and test sets. Be sure to include this, either in your dataset section or in your methods section!
How to describe a deep learning architecture?
 |
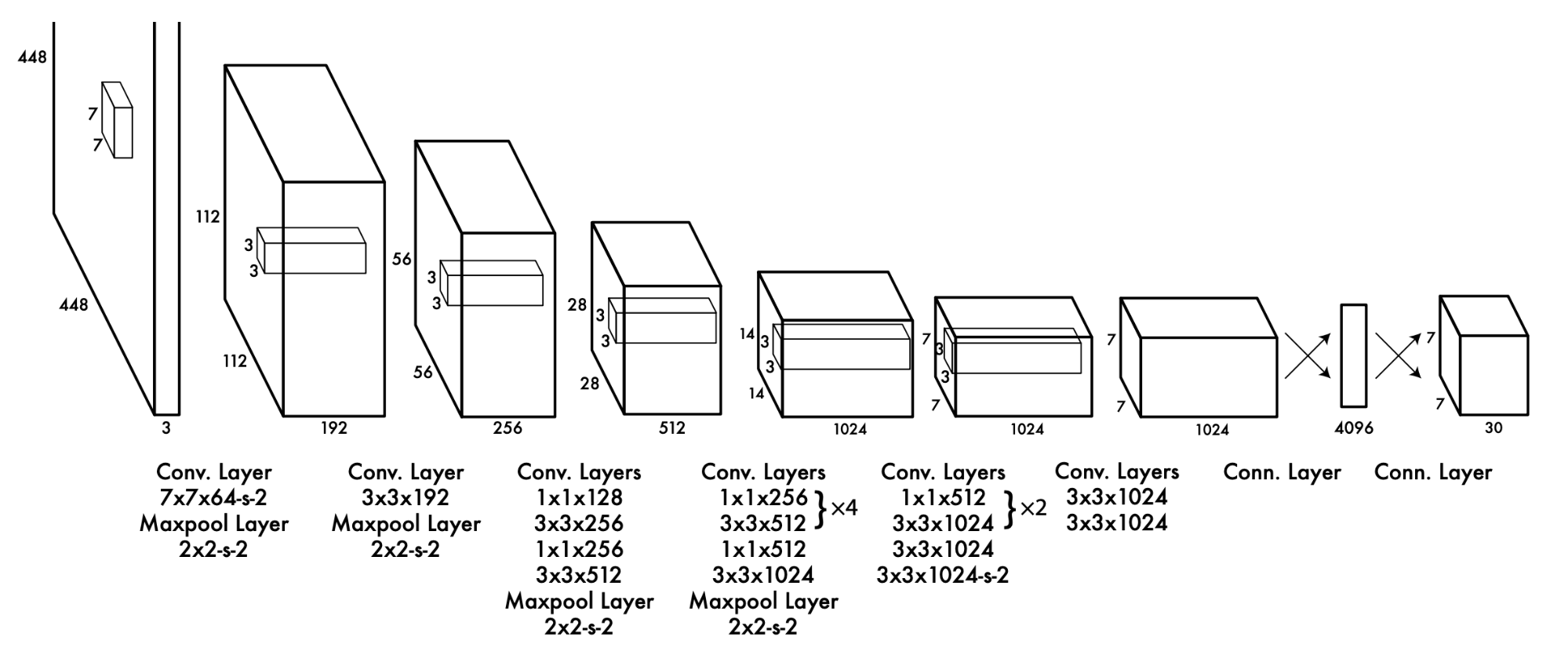 |
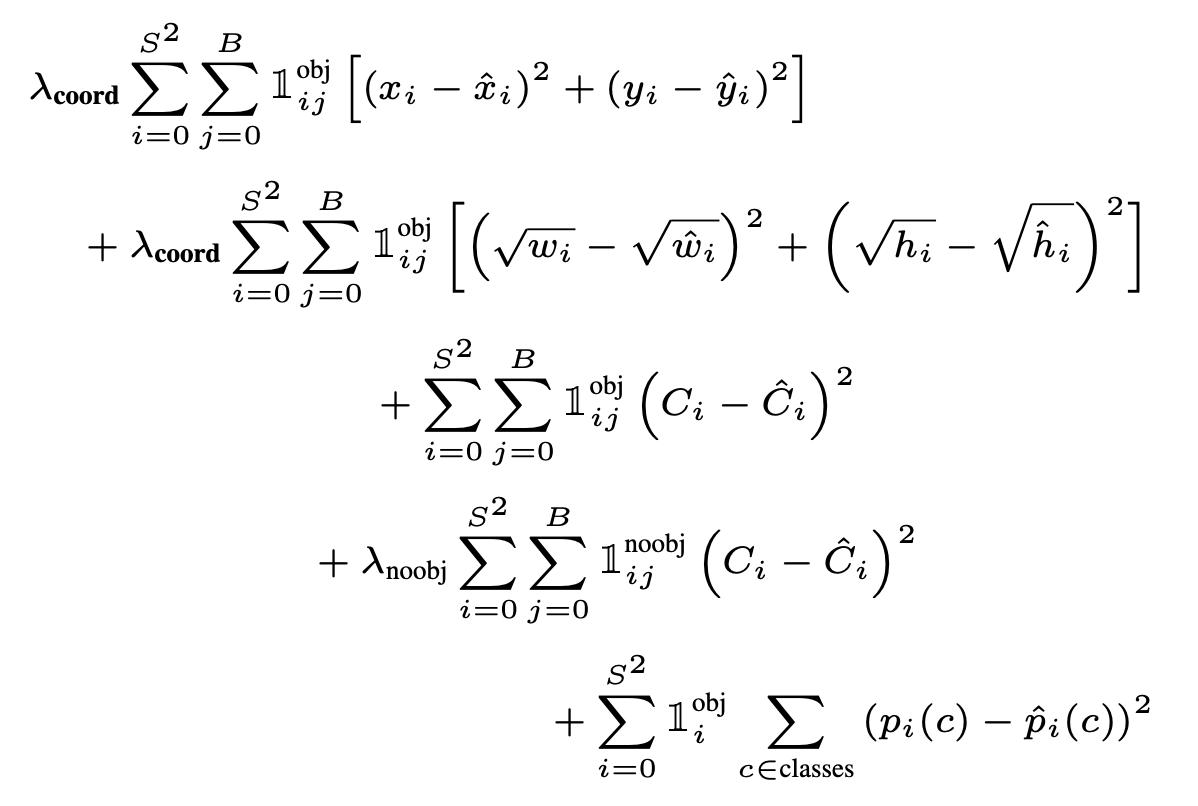 |
Why is this good?
- Model architecture is drawn clearly. Convolutions and maxpool are shown with their hyperparameters.
- Dimensions of each layer are also shown clearly for ease of re-implementation.
- Key insight of dividing image into grids and using each grid to do bounding box regression is clear from the first image. (Always remember what you want the audience to take away from your paper. It’s not always just about drawing the model architecture. For example, if your key insight is a certain type of data augmentation for example, use a diagram to illustrate it and compare it with other types of data augmentation).
- Loss function is another key insight in this paper since it’s about repurposing regressors for object detections. Hence, describing the loss function is importance in this case. But it’s not always important. If you’re using a common loss function such as cross-entropy loss, there’s no need to write down the formula.
Other interesting points:
- Loss function: Why sqrt the width and height before taking L2 distance? (think ratios. If the actual width is 10 and prediction is 11 vs. if actual width is 1 and prediction is 2).
- Repurposing regressors as object detectors (vs. RCNN which uses classifiers as object detectors).
How to describe a deep learning architecture (for GANs)
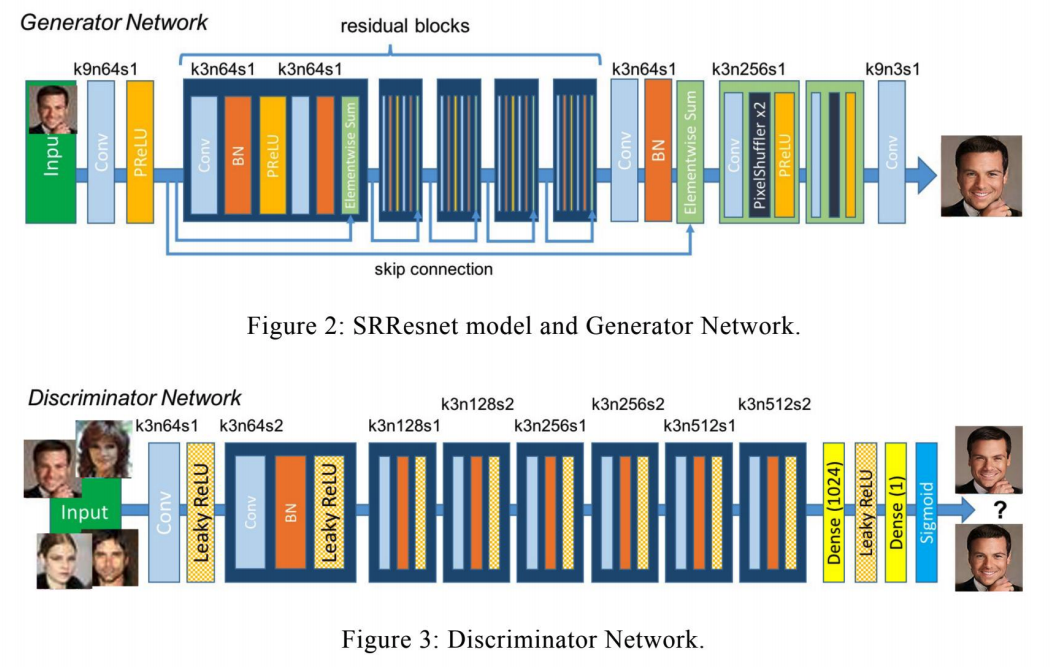 |
Why is this good?
- Clear description of model architecture of both generator and discriminator for ease of reimplementation.
How can this be improved?
- Also describe the output size at each layer for ease of re-implementation.
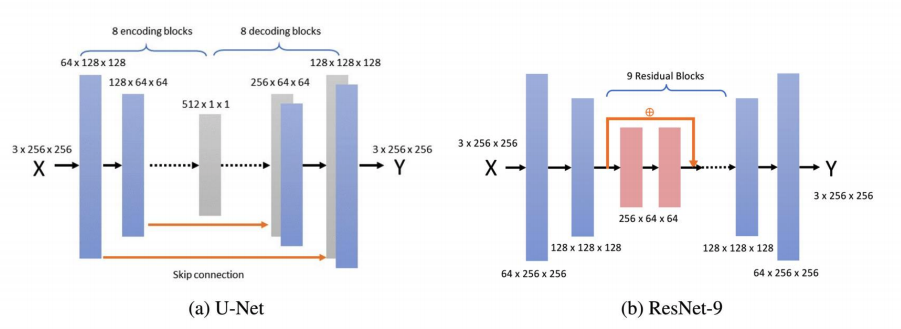 |
Why is this good?
- Quickly see the difference between the two types of architecture that are being compared: U-Net and ResNet.
How can this be improved?
- Describe the actual conv params and maxpool params used. (Refer to YOLOv1)
GAN Qualitative Evaluation
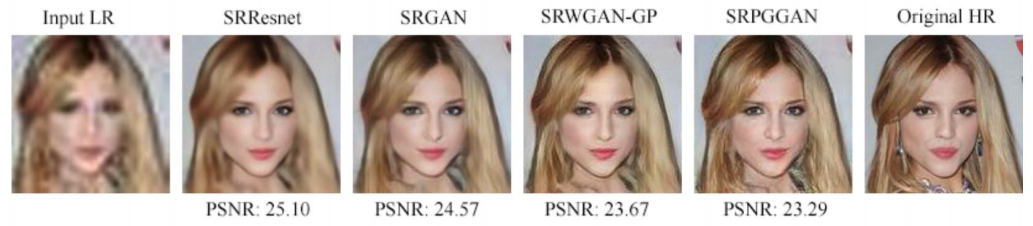 |
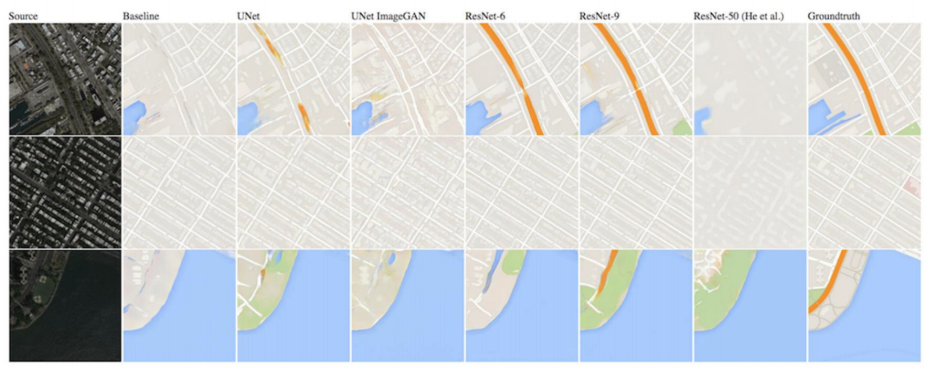 |
 |
Why is this good?
- Quick comparison between different approaches
- Quantitative figures are also given in the top figure since the images themselves are hard to differentiate.
- See the CycleGAN paper for more nice figures.
How can this be improved?
- For more convincing evaluation, don’t curate (hand pick and choose) your generated images, and tell your user your figures are uncurated. See https://arxiv.org/pdf/1812.04948.pdf for great examples.
GAN Quantitative Evaluation
- Classifying using GANs as Feature Extractor
- Inception Score
- Frechet Inception Distance
- For a great overview, see Ali Borji’s paper summarizing GAN evaluation measures.
How to describe hyperparameter tuning steps?
A general approach could be:
Step 1: Describe which hyperparameters you tuned.
Step 2: Explain why you chose to tune these hyperparameters.
Step 3: Elaborate on how you tuned these hyperparameters. (e.g. Did you use a dev set or train-dev set or leave-one-out cross validation? Was there a variance/bias problem? What range of hyperparameters did you use? Any other fancy approaches such as Bayesian Optimization?)
Step 4: State the results of tuning these hyperparameters.
Step 5: Conclude by saying which hyperparameters you tuned were the most sensitive to the performance of your model.
The key here is in the explanation. Instead of blindly tuning all your hyperparameters, it is better to focus on a few hyperparameters that you believe is important. Doing so also helps the reader reimplement your paper since they understand which hyperparameters they should focus on tuning.
How to present classification results and handle unbalanced datasets?
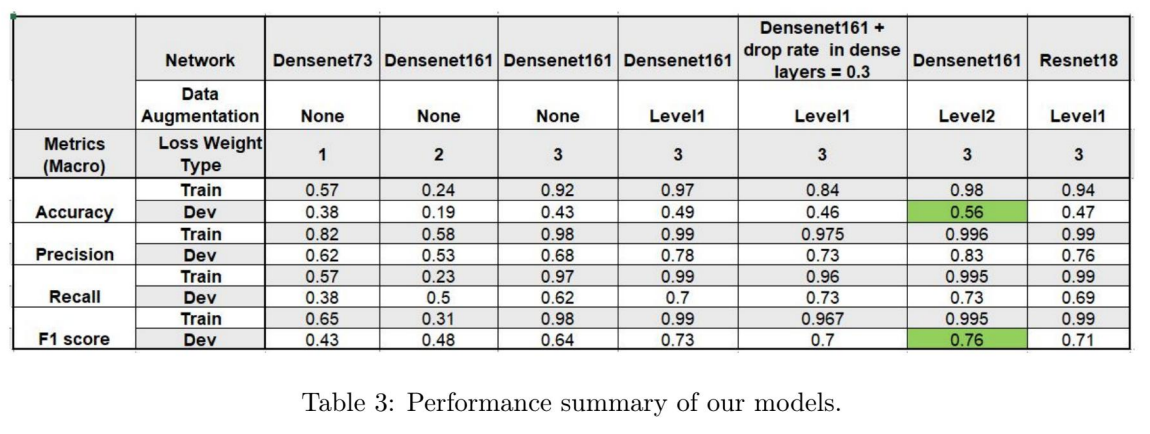 |
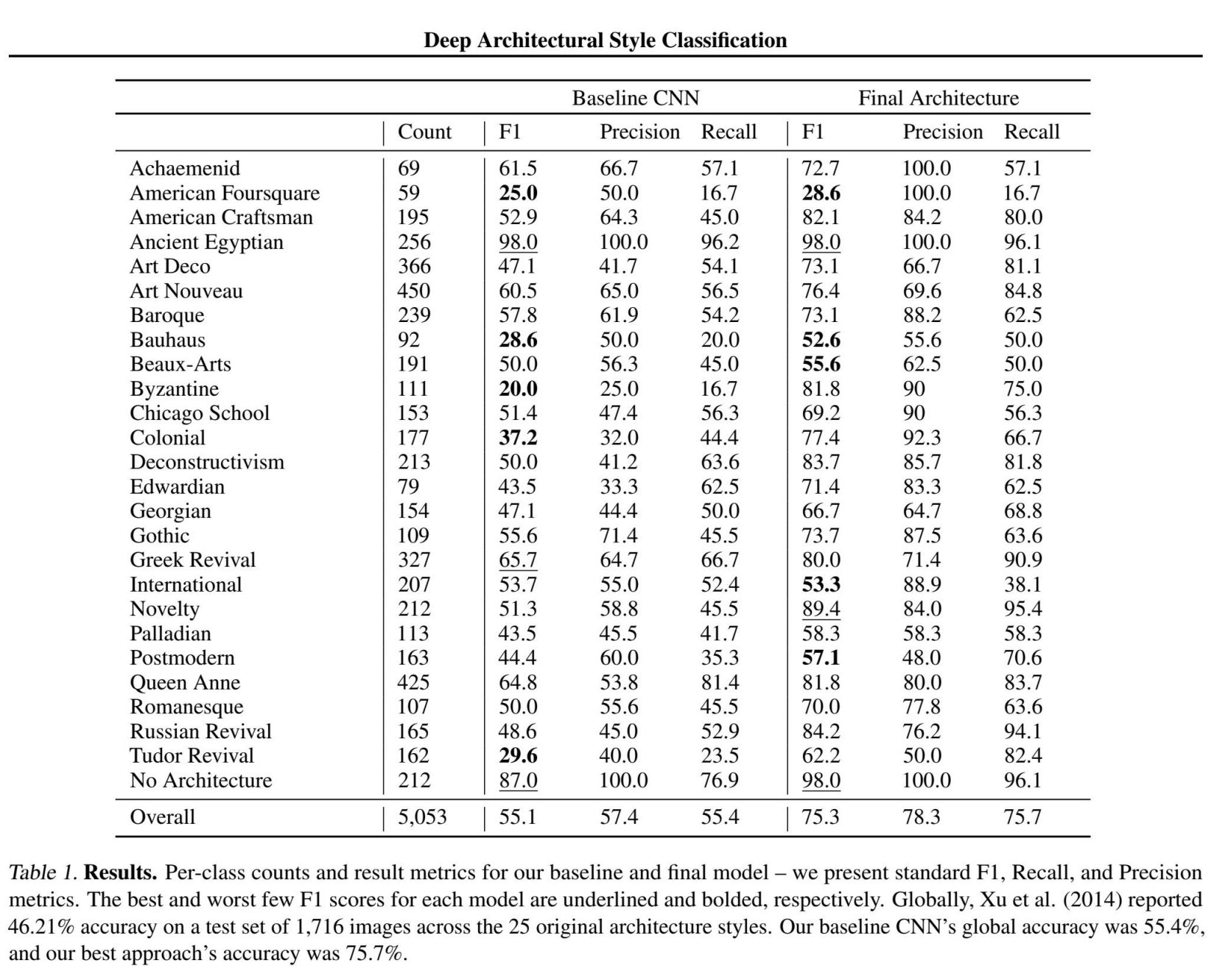
Why is this good?
- Presents all metrics clearly in the table with the most relevant hyperparameters and architectures.
- Highlights best results.
- Uses F1 score, Precision and Recall to evaluate since dataset is unbalanced.
 |
 |
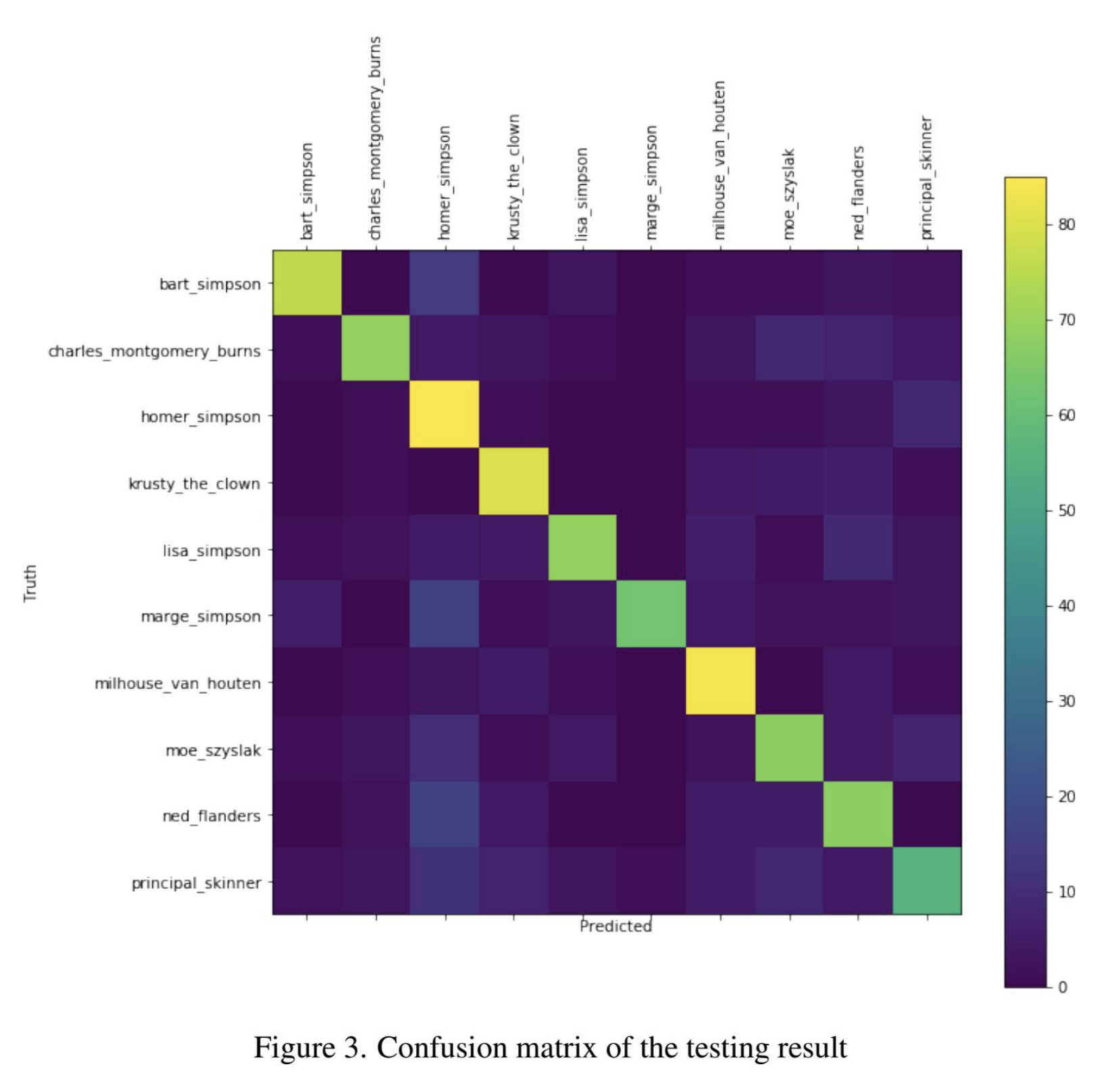
Why is this good?
- We can see how the classifier does on each individual class, as well as holistically. This works with any dataset balance!
- Having counts of number of examples of each class is great. Highlighting the best model for each row helps immensely with readability.
How to cite other publications and projects?
 |
Why is this good:
- All authors are listed, and all citations are in a standard format.
- Conference/venue listed and year
- Can do this automatically using BibTeX or Word, with in-text citations linking to the referenced citation.